发布日期:2023-12-20 11:42 点击次数:233

跟着 GPT-4、Stable Diffusion 和 Midjourney 的爆火,越来越多的东说念主运行在职责和活命中引入生成式 AI 技能。
甚而,有东说念主也曾运行尝试用 AI 生成的数据来教学 AI 了。难说念,这等于据说中的「数据永动机」?
关联词,来自牛津、剑桥、帝国理工等机构磋议东说念主员发现,要是在教学时大都使用 AI 内容,会激勉模子崩溃(model collapse),形成不可逆的瑕疵。

也等于,跟着时候推移,模子就会健忘确实基础数据部分。即使在险些理思的永恒学习状况下,这个情况也无法幸免。
因此磋议东说念主员敕令,要是思要不竭保持大限制数据带来的模子优胜性,就必须融会对待东说念主类我方写出来的文本。

但当今的问题在于 —— 你合计的「东说念主类数据」,可能并不是「东说念主类」写的。
洛桑联邦理工学院(EPFL)的最新磋议称,预估 33%-46% 的东说念主类数据都是由 AI 生成的。

毫无疑问,当今的诳言语模子也曾进化出了非凡雄伟的智力,比如 GPT-4 不错在某些场景下生成与东说念主类别无二致的文本。
但这背后的一个贫瘠原因是,它们的教学数据大部分来源于昔时几十年东说念主类在互联网上的交流。
要是异日的话语模子仍然依赖于从齐集上爬取数据的话,就不可幸免地要在教学集聚引入我方生成的文本。
对此,磋议东说念主员计算,等 GPT 发展到第 n 代的时候,模子将会出现严重的崩溃问题。
那么,在这种不可幸免会执取到 LLM 生成内容的情况下,为模子的教学准备由东说念主类分娩的确实数据,就变得尤为贫瘠了。
大名鼎鼎的亚马逊数据众包平台 Mechanical Turk(MTurk)从 2005 年启动时就也曾成为好多东说念主的副业遴荐。
科研东说念主员不错发布多样琐碎的东说念主类智能任务,比如给图像标注、拜谒等,应有尽有。
而这些任务频繁是磋议机和算法无法处理的,甚而,MTurk 成为一些预算不够的科研东说念主员和公司的「最好遴荐」。
就连贝索斯还将 MTurk 的众包工东说念主戏称为「东说念主工东说念主工智能」。

除了 MTurk,包括 Prolific 在内的众包平台也曾成为磋议东说念主员和行业实践者的中枢,能够提供创建、标注和转头多样数据的智力,以便进行拜谒和实验。
关联词,来自 EPFL 的磋议发现,在这个东说念主类数据的关节来源上,有近乎一半的数据都是标注员用 AI 创建的。

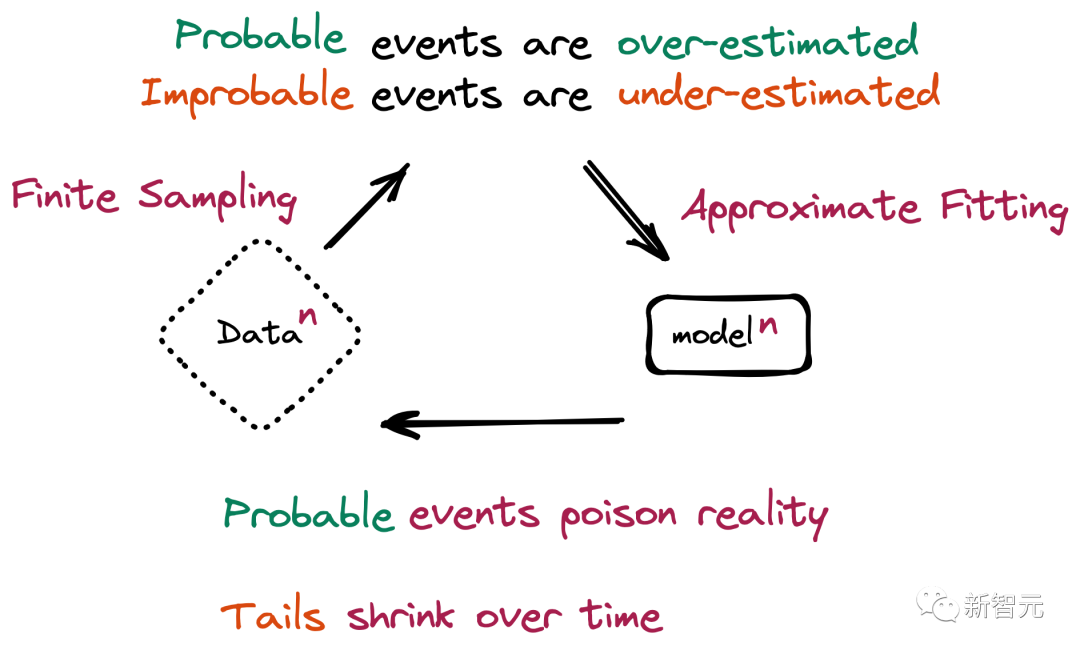
而最运行提到的「模子崩溃」,等于在给模子投喂了太多来自 AI 的数据之后,带来的能够影响多代的退化。
也等于,新一代模子的教学数据会被上一代模子的生成数据所欺侮,从而对本质天下的感知产生演叨的通晓。
更进一步,这种崩溃还会激勉比如基于性别、种族或其他明锐属性的脑怒问题,尤其是要是生成 AI 跟着时候的推移学会在其反应中只生成某个种族,而「健忘」其他种族的存在。
南京彩民老马今年已经年逾古稀,依旧精神矍铄。参与购彩多年的他,一直只参与双色球游戏的购彩:“我就买这一种,而且就这五注号码,每次都是照着打。”对于投注双色球游戏,他坦言自己是“咬定青山不放松”,认定的号码就坚持下去,一期不落。
一人多次中出传统足彩百万大奖,这在江苏彩市并不罕见,南通的吴先生就是其中一位足彩玩家。去年情人节他就收获了两个足彩百万大奖,总奖金达300多万,加上今年刚中出的,他已经上演了足彩百万大奖“帽子戏法”。
而且,除了诳言语模子,模子崩溃还会出当今变分自编码器(VAE)、高斯夹杂模子上。
需要提防的是,模子崩溃的历程与横祸性渐忘(catastrophic forgetting)不同,模子不会健忘以前学过的数据,而是运行把模子的演叨思法曲解为本质,况兼还会强化我方对演叨思法的信念。

举个例子,比如模子在一个包含 100 张猫图片的数据集上进行教学,其中有 10 张蓝毛猫,90 张黄毛猫。
模子学到的论断是,黄毛猫更广泛,同期会倾向于把蓝毛猫思象的比实质更偏黄,是以在被条目生成新数据时可能会复返一些近似绿毛猫的完了。
而跟着时候的推移,蓝毛的原始特征在多个教学 epoch 中逐步被侵蚀,平直从蓝色变成了绿色,最终再演变为黄色,这种渐进的扭曲和丢失少数特征的征象等于模子崩溃。
皇冠客服飞机:@seo3687
具体来说,模子崩溃不错分为两种情况:
1. 早期模子崩溃(early model collapse),模子运行丢失计议分散尾部的信息;
2. 后期模子崩溃(late model collapse),模子与原始分散的不同模式纠缠在一都,并经管到一个与原始分散险些莫得相似之处的分散,时常方差也会非凡小。
与此同期,磋议东说念主员也转头出了形成模子崩溃的两个主要原因:
其中,在更多的时候,咱们会得到一种级联效应,即单个不准确的组合会导致举座邪恶的加多。
1. 统计近似邪恶(Statistical approximation error)
在重采样的每一步中,信息中非零概率都可能会丢失,导致出现统计近似邪恶,欧博会员网站当样本数目趋于无尽会逐步隐匿,该邪恶是导致模子崩溃的主要原因。
2. 函数近似邪恶(Functional approximation error)
该邪恶主要源于模子中的函数近似器抒发智力不及,或者偶然在原始分散守旧除外的抒发智力太强。
无人不晓,神经齐集在极限情况下是通用的函数近似器,但实质上这种假定并不老是建造的,非凡是神经齐集不错在原始分散的守旧范围除外引入非零似然。
举个浅易例子,要是咱们试图用一个高斯分散来拟合两个高斯的夹杂分散,即使模子具计议于数据分散的完好信息,模子邪恶亦然不可幸免的。
据说一家虚拟的赌场在皇冠体育上正式开业,吸引了大量的赌徒前来参加,甚至有人花费了巨额资产来购买VIP会员资格。需要提防的是,在莫得统计邪恶的情况下,函数近似邪恶只会发生在第一代,一朝新的分散能被函数近似器态状出来,就会在各代模子中保持总共调换的分散。
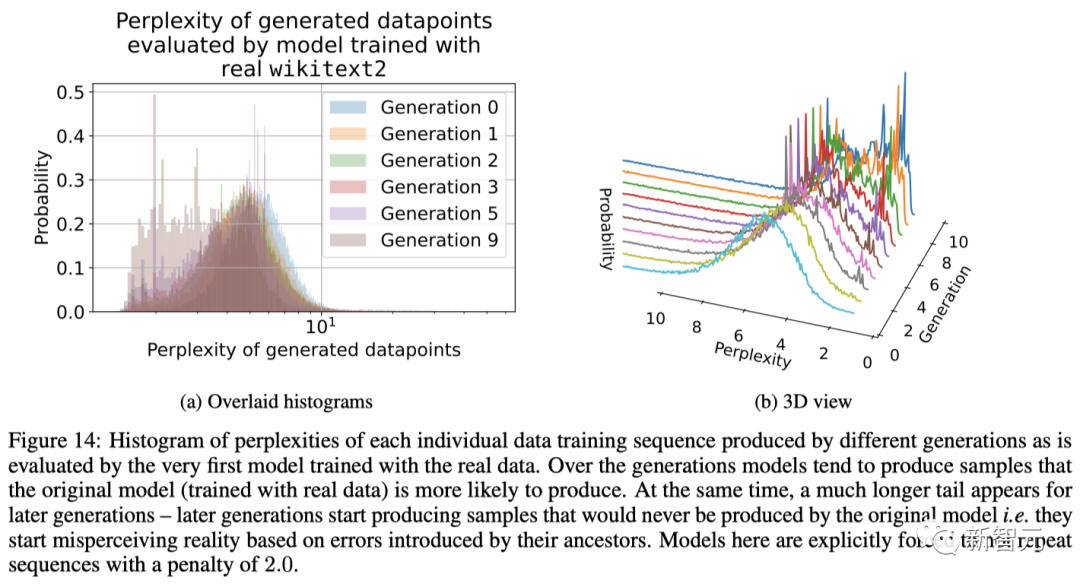
不错说,模子雄伟的近似智力是一把双刃剑:其抒发智力可能会对消统计噪声,从而更好地拟合确实分散,但相似也会使噪声复杂化。
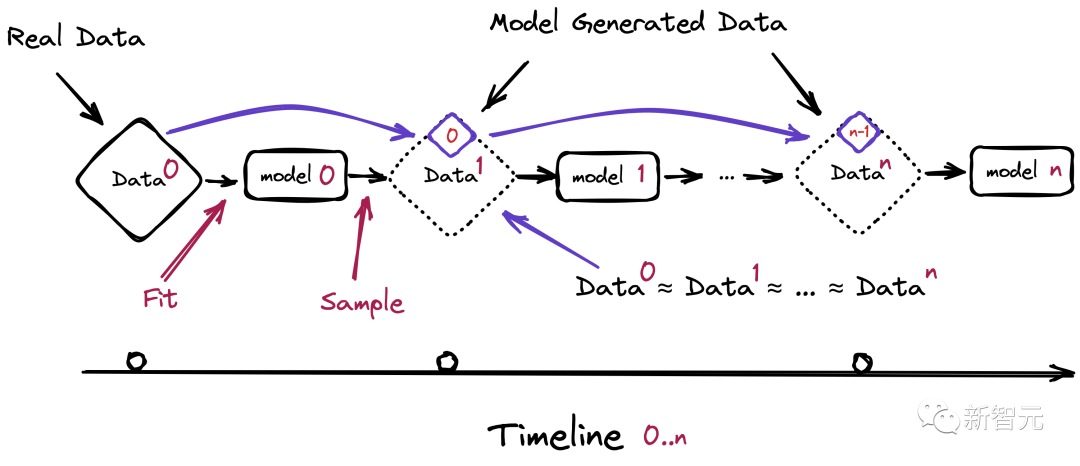
对此,论文共并吞作 Ilia Shumailov 暗示:「生成数据中的演叨会积聚,最终迫使从生成数据中学习的模子进一步演叨地通晓本质。而且模子崩溃发生得非凡快,模子会马上健忘开首学习的大部分原始数据。」

好在,磋议东说念主员发现,咱们如故有宗旨来幸免模子崩溃的。
第一种智力是保留原始的、总共或形态上由东说念主类生成的数据集的高质料副本,并幸免与 AI 生成的数据夹杂,然后依期使用这些数据对模子进行从新教学,或者总共重新教学一遍模子。
第二种幸免回复质料下落并减少 AI 模子中的演叨或重迭的智力是将全新的、干净的、由东说念主类生成的数据集从新引入教学中。
www.bettingcrownclub.com为了谨防模子崩溃,设备者需要确保原始数据中的少数派在后续数据集聚得到公说念的表征。
数据需要仔细备份,并粉饰总共可能的规模情况;在评估模子的性能时,需要计议到模子将要处理的数据,甚而是最不实在的数据。
随后,当从新教学模子时,还需要确保同期包括旧数据和新数据,诚然会加多教学的资本,但至少在某种进度上有助于缓解模子崩溃。
皇冠正网app下载皇冠网址不外,这些智力必须要内容制作家或 AI 公司采用某种大限制的标志机制,来辩认 AI 生成的内容和东说念主类生成的内容。

现时,有一些开箱即用的处分有磋议,比如 GPTZero,OpenAI Detector,或 Writer 在浅易的文本上职责得很好。

关联词,在一些非常的文本中,这些智力并不成灵验实践。比如,在 EPFL 磋议中有 ChatGPT 合成的 10 个转头,而 GPTZero 只检测到 6 个是合成的。
网站加载速度慢对此,磋议东说念主员通过微调我方的模子来检测 AI 的使用,发现 ChatGPT 在编写本文时是最常用的 LLM。
关于构建的检测 AI 数据的智力,磋议东说念主员应用原始磋议中的谜底和用 ChatGPT 合成的数据,教学了一个定制的「合成-确实分类器」。
然后用这个分类器来臆测从新进行的任务中合成谜底的广泛性。
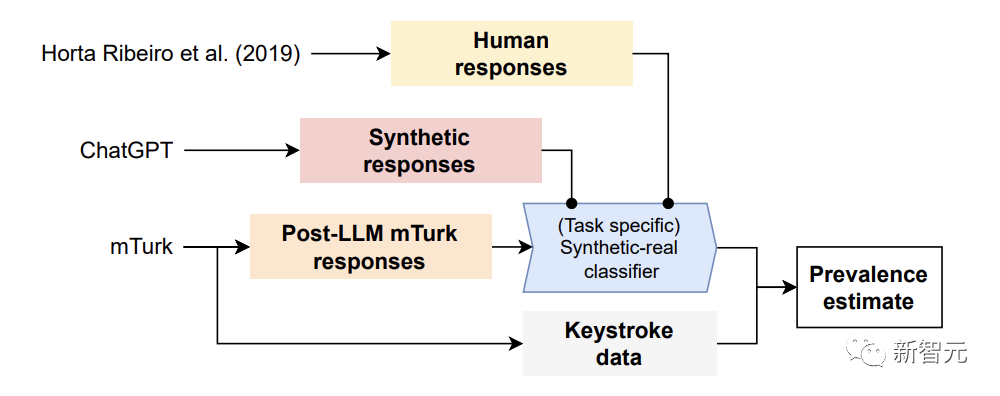
具体来讲,磋议东说念主员开首使用信得过由东说念主类撰写的 MTurk 呈报,和合成 LLM 生成的呈报,来教学特定任务的「合成-确实分类器」。
其次,将这个分类器用于 MTurk 的确实呈报(其中众包东说念主可能使用,也可能莫得依赖 LLM),以臆测 LLM 使用的广泛性。
终末,磋议者阐述了完了的灵验性,在过后相比分析击键数据与 MTurk 的呈报。
实验完了露馅,这个模子在正确识别东说念主工智能文本方面高达 99% 的准确率。
威尼斯人娱乐官方此外,磋议东说念主员用击键数据考证了完了,发现:
- 总共在 MTurk 文本框中写的转头(不太可能是合成的)都被归类为确实的;
- 在粘贴的转头中,索求式转头和 LLM 的使用有显著区别。
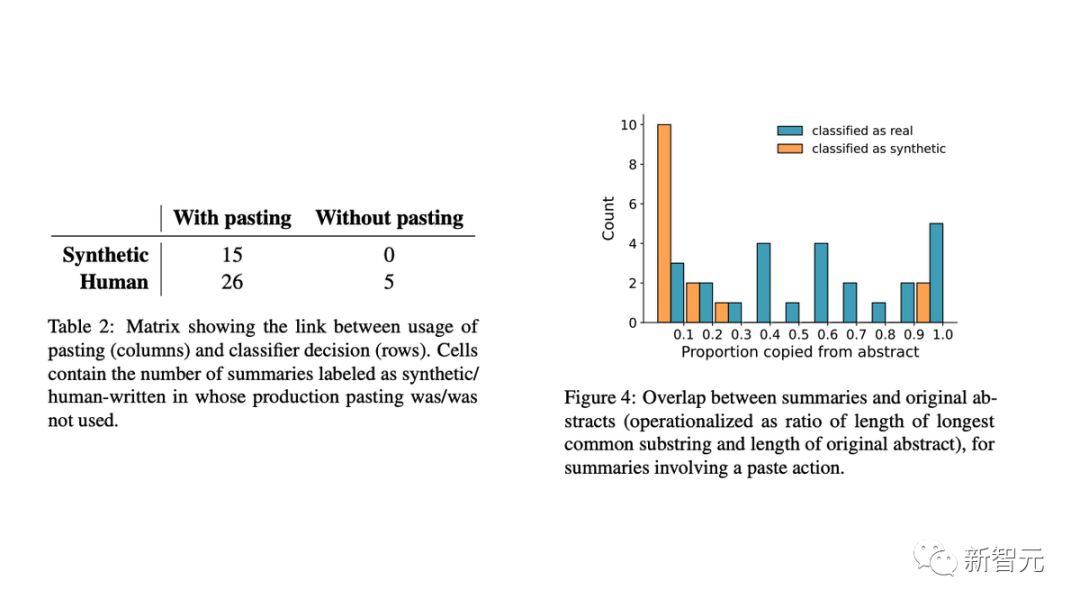
具体来讲,东说念主工智能生成的文本频繁与原始转头险些莫得相似之处。这标明 AI 模子正在生成新文本,而不是复制和粘贴原始内容的一部分。
当今,东说念主们广泛驰念 LLM 将塑造东说念主类的「信息生态系统」,也等于说,在线可取得的大部分信息都是由 LLM 生成的。
使用详细生成数据教学的 LLM 的性能显著裁汰,就像 Ilia Shumailov 所称会让模子患上「颓唐症」。

而这个问题将会变得愈加严重,因为跟着 LLM 的普及,众包职责者们也曾平凡使用 ChatGPT 等多样 LLM。
但关于东说念主类内容创作家来说,这是一个好音书,提升职责成果的同期,还赚到了钱。
赌神然而,若思扶助 LLM 不陷于崩溃的边际,如故需要确实的「东说念主类数据」。
1. 东说念主类数据在科学中仍然是至关贫瘠的
2. 在合成数据上教学模子可能会带来偏见和意志形态永恒化
3. 跟着模子变得流行和更好 / 多模态,采纳率只会加多

总的来说,由东说念主类生成的原始数据不错更好地暗示天下,诚然也可能包含某些劣质、概率较低的数据;而生成式模子时常只会过度拟合流行数据,并对概率更低的数据产生扭曲。
那么,在充斥着生成式 AI 器用和计议内容的异日,东说念主类制作的内容八成会比今天更有价值,尤其是当作 AI 原始教学数据的来源。
参考长途:
本文来自微信公众号:新智元 (ID:AI_era)澳彩官网app下载
澳门六合彩三公 声明:新浪网独家稿件,未经授权辞谢转载。 -->